
Genética
y Biología Molecular
Genetics and Molecular Biology
Víctor
Antonio Tejeda Moreno
Instituto de Ciencias de la Salud, Universidad
Veracruzana
RESUMEN
PALABRAS CLAVE
INTRODUCCIÓN
Las relaciones
entre
Resulta difícil leer o estudiar un libro de medicina
interna contemporáneo, cuyos capítulos no traigan como
su inicio el enunciado: El impacto de
El presente trabajo encuentra su justificación en que,
realizando relaciones binarias se han explorado las
relaciones existentes entre
Fue hasta el siglo XVII cuando Malpighi propuso
la hipótesis del homúnculo o de la preformación que
dice que el organismo por entero se encuentra completamente
preformado en el óvulo y que, posteriormente, sólo crece.
Aún después del descubrimiento del espermatozoide en
1677 se mantuvo la hipótesis de la preformación, pero
con la variante de que algunos creían que el individuo
se encontraba preformado en el semen y que solamente
se desarrollaba gracias a la madre.
Curiosamente, en la literatura médica del siglo
XVIII y principios del XIX, se encuentran consignados
algunos hechos que nos demuestran
que a veces la pura observación es suficiente
para interpretar la herencia de algunas enfermedades.
Maupertuis, por ejemplo, describió en 1752 una familia
con polidactilia en cuatro generaciones y consignó que
la anormalidad era transmitida tanto por el padre como
por la madre. Como hoy sabemos, la polidactilia que
este autor reportó, se transmite de manera autosómica
dominante1.
Ya en los siglos XVIII y XIX, anteriores a Mendel,
están los de Knight en 1799 y los de Goss en 1824. Ambos
autores trabajaron con el chícharo, la misma planta
que Mendel ocuparía.
Todos los individuos tienen genes,
cuyo número para nuestra especie ha sido precisado como
de
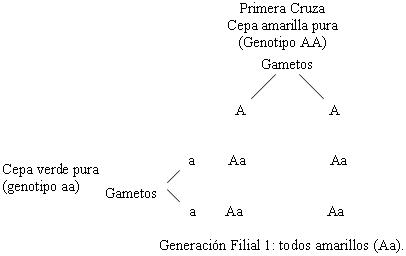
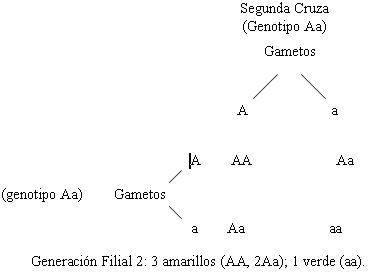
Mendel obtuvo siempre, en todos sus experimentos
la proporción 3:1, aunque estudiara miles de plantas
de chícharos y las 7 características que en ellas estudió,
por ejemplo: color y altura de las plantas. Los estudios
de Mendel son demasiado conocidos como para que abunde
más en ellos, sólo quisiera destacar que la proporción
3:1 fue determinante para las conclusiones de Mendel.
Veamos dos ejemplos.
La herencia mendeliana monogénica o
simple, lo mismo la autonómica que la ligada al cromosoma
X, puede ser dominante, recesiva o codominante. El sistema
de grupos sanguíneos ABO sirve para ejemplificar las
tres situaciones: 1.- Los individuos homocigotos para
el gen A (dosis doble) o heterocigotos para los genes
A y O, son fenotípicamente de grupo sanguíneo A y un
fenómeno similar ocurre para los individuos BB y BO,
que son del grupo B; en ambos casos A y B son dominantes
en relación al gen O; 2.- El grupo sanguíneo O sólo
se da en sujetos homocigotos para este gen, por lo que
es recesivo, y 3.- Las personas con un gen A y el otro
B tienen el grupo AB, por lo que A y B son codominantes1, 3, 4.
La primera evidencia experimental amplia de herencia
ligada al sexo en una especie con machos heterogaméticos
la realizó en 1910 T. H. Morgan, con el descubrimiento
de un mutante de ojos blancos en Drosofila. Un solo macho de ojos blancos apareció en un cultivo de
moscas de ojos rojos. Evidentemente, un gen había sufrido
un cambio o mutación que resultó en la alteración de
una o más reacciones bioquímicas en el desarrollo de
la mosca y los ojos fueron blancos en lugar de rojos.
El macho de los ojos blancos se cruzó con una hembra
de ojos rojos. Las moscas F1 fueron todas de ojos rojos, pero
Debido a que la mosca macho tenía solamente un
cromosoma X y un cromosoma diferente Y, se postuló que
un gen simple para los ojos rojos era capaz de expresarse
en ausencia de su alelo. La palabra hemicigoto se usa para describir aquellos machos que tiene
sólo un miembro de un par alelomorfo de genes. En el
humano, el varón es hemicigoto, porque posee un cromosoma
Y del padre y un cromosoma X de la madre. Volviendo
a la mosca, el gen mutado presenta en el cromosoma X
de los machos de ojos color blanco originales, paso
a sus hijas y transmitieron un cromosoma Y a sus hijos.
Todas las hijas, por tanto, eran portadoras del gen.
Los machos F2 hemicigóticos obtuvieron su cromosoma X de sus madres
heterocigóticas. El 50% de ellos recibieron el gen w+
y desarrollaron ojos rojos, y el otro 50%, recibió el
gen w y desarrollo ojos blancos. Las proporciones iguales
de ojos rojos y ojos blancos en los machos F2 se explicaron sobre la base de la
segregación de los cromosomas X de las madres F1 a sus hijos.
¿Pudieron aparecer hembras de ojos blancos? A
partir de la hipótesis de que el gen era llevado en
el cromosoma X, Morgan predijo que se podía originar
una hembra del genotipo ww y tendría los ojos blancos.
Esto se probó experimentalmente cuando se hicieron cruzamientos
entre machos con ojos blancos y hembras F1 con ojos rojos (ww+). De estas cruzas,
la mitad de la cantidad de las hembras así como la mitad
de la de los machos tuvieron ojos blancos como se había
predicho. Los machos y las hembras de ojos blancos se
cruzaron entonces y se produjo así un cultivo de moscas
de ojos blancos, línea que fue establecida y mantenida
y se encuentra en la actualidad en no pocos laboratorios
de Genética. Desde el hallazgo de Morgan, la mutación
de ojos blancos ha ocurrido espontáneamente en varias
ocasiones.
En el humano, la expresión ligada al X se usa
para precisar que un gen se encuentra en el cromosoma
X, tal y como ocurre en las hemofilias A y B. Las mujeres
son portadoras y transmisoras; los hombres padecen la
alteración en un 50%. Ahora bien, existen excepciones:
una mujer podía padecer una hemofilia o un síndrome
de Taybi, si el cromosoma X portador del gen alterado
se inactiva, como en efecto ha ocurrido. La mujer es,
cromosómicamente hablando, XX; el varón es XY. Uno de
los cromosomas X de la mujer se inactiva, siguiendo
En 1902 Archibald Garrod publica su artículo
En 1869 el médico suizo Friedrich Miescher, trabajaba
en el laboratorio del bioquímico alemán Felix Hoppe-Seyler,
en leucocitos que obtenía del pus de pacientes que estaban
en el posoperatotio. Miescher encontró una sustancia
que formaba un precipitado cuando era tratada con álcalis,
rica en carbono, hidrógeno, oxígeno, nitrógeno y un
elevado porcentaje de fósforo; nuestro autor llamó a
la sustancia nucleína y, más tarde, cuando se percató
de su carácter ácido, la denominó ácido nucleico.
Sesenta años después, en la década de los 30´s
del siglo pasado, Phoebus Levene, ayudado por Albrecht
Kossel realizó estudios bioquímicos más profundos y
descubrió que el ácido nucleico de Miescher estaba compuesto
por:
1.- Una base nitrogenada heterocíclica.
2.- Una pentosa, es decir, un azúcar
de cinco carbonos y un radical oxidrilo que es la 2´-desoxi-D-ribosa.
3.- Ácido fosfórico a manera de fosfato
(PO4).
Hablando con más propiedad, el autor citado encontró
cuatro bases nitrogenadas heterocíclicas: adenina (A),
guanina (G), citosina (C) y Timina (T). Las dos primeras
son púricas,
y C y T son pirimídicas. Las cuatro bases provienen
del benceno y las dos primeras tienen dos anillos. Como
veremos, en el RNA
Todos los nucleótidos en una cadena polinucleotídica
tienen la misma orientación relativa, de modo que si
en el primer nucleótido el carbono 5´ está por encima
del anillo de pentosa y el carbono 3´ por debajo, la
posición del carbono 5´ se mantiene en los nucleótidos
restantes. Por tanto, una cadena polinucleotídica es
direccional y la dirección de avance se define como
5´ → 3´, es decir, partiendo del C-5´ del azúcar,
a través del C-4´, al C-3´ que conecta con el siguiente
fosfato. Los extremos de las cadenas polinucleotídicas
se denominan 5´ y 3´, denotando la dirección de las
cadenas. Los enlaces fosfodiéster de las dos hebras entrelazadas avanzan en dirección
opuesta, es decir, las dos cadenas son antiparalelas.
Esto se debe a que los dos esqueletos de azúcar fosfato
rodean el exterior de las bases como un pasamanos de
una cadena espiral y están expuestos al medio acuoso.
Los anillos aromáticos de las bases son hidrofóbicos
y se apilan en el interior casi perpendicularmente al
eje de la hélice. Como los enlaces fosfodiéster avanzan
en dirección opuesta, las dos cadenas son antiparalelas.
(vide supra).
La fracción molar de cada base en una muestra
de DNA, es decir, la composición de bases, puede determinarse
hidrolizando la muestra y analizando cuantitativamente
los productos. Debido a que la separación y el análisis
cuantitativo eran difíciles, la composición de bases
del DNA no se determinó hasta 80 años después de su
descubrimiento, cuando se inventó la técnica de cromatografía
en papel. A finales de los años 40´s Erwin Chargaff
empleó la cromatografía en papel para determinar la
composición de bases de muestras de DNA aisladas de
diferentes organismos, encontrando que el número de
moles de A y T, por un lado, y el número de moles de
C y G, por otro eran iguales. Aunque el significado
de esta observación no se comprendió por aquel entonces,
pudo explicarse más tarde en términos de la estructura
del DNA.
Así, hacia 1950 se supo que el DNA era un polímero
lineal de residuos de 2´-desoxirribonucleótidos unidos
por enlaces fosfodiéster 5´-3´ y que contenía 4 residuos
de nucleótidos distintos dA, dT, dC y dG, es decir,
las bases escritas junto con la inicial de la pentosa
(vide supra), de forma que los pares de dA y dT, y dC y dG se encuentran
en cantidades equimoleculares.
En 1953, James Watson y Francis Crick determinaros
la estructura tridimensional del DNA. Empleando los
estudios de difracción de Rayos X de fibras de DNA obtenidos
por Rosalind Franklin y Maurice Wilkins, Watson y Crick
elucidaron esa estructura mediante una combinación de
análisis de datos de difracción de Rayos X, de modelos
teóricos y de intuición. Estos autores compartieron,
en 1962, el Premio Nobel por el descubrimiento de la
estructura del DNA.
Así, se tiene que el DNA es una doble
hélice. En ella, cada una de sus dos hebras se enrolla
alrededor del eje central generalmente en forma de hélice
dextrógira. Los dos esqueletos de azúcar fosfato rodean
el exterior de las bases y protegen a éstas.
Cada Adenina de una cadena del DNA está unida
mediante enlaces de hidrógeno a
Los apareamientos AT y CG son los idóneos, mientras
que los AC y GT son improbables debido a la química
de las bases. Los átomos de hidrógeno pueden desplazarse
en las bases del DNA de un
átomo de nitrógeno o de oxígeno a otro; estos
desplazamientos de protones, llamados reacciones de
tautomerización, interconvierten las posiciones de los
dadores y los aceptores de enlaces de hidrógeno en los
apareamientos de bases. En condiciones fisiológicas
normales los equilibrios de tautomerización están desplazados
hacia las formas ceto y amino (C=O, ceto) y (C-NH2, amino).
El DNA tiene dos surcos, siendo el menor aquél
que se forma de trazar una línea imaginaria entre las
bases de las pentosas y una línea superior entre las
pentosas, se toman siempre como ángulos las bases de
la pentosa en cuestión, estos surcos mayor y menor dan
origen al ángulo menor y al ángulos mayor.
El DNA puede tomar distintas conformaciones bajo
diferentes condiciones físicas,
En los animales superiores, incluido el hombre,
el B-DNA se encuentra asociado a histonas, que son proteínas,
siendo las topoisomerasas las que cambian el número
de uniones del DNA. Al complejo DNA-histonas se le llama
cromatina.
La holoenzima DNA polimerasa III, cataliza la
síntesis de DNA en el medio intracelular, este descubrimiento
se debe a Arthur Kornberg, quien ganó el Premio Nobel.
Las moléculas de DNA, por sí solas,
no realizarían el mensaje genético; es necesario el
concurso de otras moléculas y otros elementos. Antes
de describir a los RNA (s), es necesario enunciar el
dogma central de
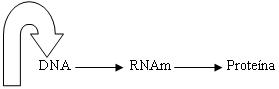
Muchos años después, H. Temin realizó una modificación
al dogma central de
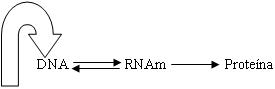
Una tercera clase de moléculas de RNA es el RNA
mensajero
(RNAm), que contiene la información que especifica la
secuencia de las proteínas. El descubrimiento del RNAm
fue debido, en gran parte, al trabajo de Jacob y Monod
y de sus colaboradores en el Instituto Pasteur de París.
A principios de los años 60´s, sus resultados pusieron
de manifiesto que los ribosomas participan en la síntesis
de proteínas traduciendo una molécula inestable de RNA,
el RNAm, y que la secuencia de este RNA es complementaria
a una de las cadenas del DNA.
En todos los organismos las moléculas de RNAm
son menos estables que las moléculas que las de RNAm
y de RNAt, el RNAr da cuenta de la mayor parte del RNA
celular, mientras que el RNAm es sólo un porcentaje
minoritario (nivel estacionario = 3%; capacidad de síntesis
= 32%). Sin embargo, si se comparan las velocidades
de síntesis del RNA con sus niveles estacionarios se
ve que la célula emplea casi un tercio de su capacidad
de síntesis de RNA en la producción de RNAm.
Al mismo tiempo que se identificó el RNAm, los
investigadores de los laboratorios de J. Hurwitz, A.
Stevens y de
S. Weiss, descubrieron independientemente una enzima
que catalizaba la síntesis de RNA a partir de una molécula
molde de DNA y ATP, UTP, GTP y CTP. (El ATP corresponde
a adenosintrifosfato, el UTP a uridintrifosfato, el
GTP a guanosintrifosfato y el CTP a citosintrifosfato.
Estas moléculas son nucleótidos cíclicos que provienen del azúcar pentosa- ribosa, que es la propia de los ARN (s),
así como los nucleótidos cíclicos que constituyen al
DNA tienen su propia fórmula que empieza con d, por
la pentosa de este ácido. El ATP se considera la moneda
de cambio de la célula, su principal función es la de
proveer de energía a muchos procesos biológico moleculares,
entre otros la de formar parte de los RNA(s).) Esta
enzima descubierta es
Muchos años antes de que Jacob y Monod hicieran
su descubrimiento, en Alemania Felix Hoppe-Seyler, descubrió
una sustancia muy similar al DNA, que obtuvo a partir
de levaduras, inicialmente, para posteriormente encontrarla
en animales; se creyó que esta sustancia estaba en animales
superiores debido al alimento vegetal de los mismos.
Estas ideas prevalecieron hasta 1914 cuando Robert Feulgen
descubrió un colorante que teñía el DNA, pero no el
RNA, y otro que teñía sólo el RNA; al teñir células
con ambos colorantes descubrió la presencia conjunta
de DNA y RNA en las mismas.
El esqueleto covalente del RNA consiste en un
polímero lineal de unidades ribonucleotídicas unidas
mediante enlaces fosfodiéster 5´-3´. En este aspecto
el DNA y el RNA son muy parecidos, no obstante, el RNA
se diferencia estructuralmente del DNA en tres puntos
importantes.
2.- La timina es sustituida por uracilo
(U) en lo que se refiere a las bases nitrogenadas. Recuérdese
que la timina posee un grupo metilo (CH3) en el C-5 cuya sustitución por un hidrógeno resulta
en el uracilo. Las bases nitrogenadas comunes del RNA
son la adenina, el uracilo, la guanina y la citosina.
3.- Las moléculas de RNA son generalmente
monocatenarias. Sin embargo, en una única cadena de
RNA el apareamiento de bases de Watson-Crick puede ocurrir
entre la adenina y el uracilo y la guanina y la citosina,
y resultar en toda clase de estructuras secundarias,
entre las que cabe citar las estructuras en bucle y
en horquilla que participan en el reconocimiento del
RNA por proteínas.
Unas cuantas cadenas de RNA son bicatenarias
y su conformación es análoga a la del A-DNA. En este
sentido, la doble hélice de RNA completa una vuelta
cada once pares de bases; los pares de bases se encuentran
inclinados lejos del eje central de la hélice, de forma
que permite la solvatación de los grupos oxidrilo en
los C-2´ de los azúcares. La existencia de una hélice
doble de RNA similar del B-DNA no es posible debido
a que los grupos 2´ oxidrilo no se encontrarían solvatados.
Estructuras helicoidales bicatenarias en las
que una cadena es DNA y la otra RNA existen en las células
en varios momentos. Por ejemplo, en la transcripción
(vide supra) se forma una molécula de RNA,
copia de una cadena de DNA en una reacción catalizada
por
Si bien el DNA es el depositario celular
de la información genética, muchas moléculas de RNA
participan en el proceso de expresión de tal información.
En una célula dada, las moléculas de RNA se encuentran
en múltiples copias y formas. La síntesis de RNA o transcripción
(vide supra)
se lleva a cabo muy precisamente.
Las moléculas de RNA se clasifican atendiendo
a su localización celular y a su función. De este modo,
en las células procarióticas se diferencian tres formas
mayoritarias de RNA:
1.- El RNA mensajero (mRNA), que transporta la información genética del DNA a
los ribosomas, organelos subcelulares responsables de
la biosíntesis de proteínas.
2.- El RNA ribosómico (rRNA), que es una parte constitutiva de los ribosomas
y que arroja aproximadamente el 75%
del RNA celular. En una célula determinada hay
varias especies moleculares de RNA, que corresponden
a los veinte tipos de alfa-aminoácidos que existen en
la naturaleza.
3- El RNA de transferencia (tRNA), que transporta los residuos de aminoácidos que
son adicionados a las cadenas polipeptídicas crecientes
durante la biosíntesis de proteínas.
Estos tres tipos de RNA fueron los primeros para
los que se describió una función bioquímica. Las células
eucarióticas
contienen, además de estos tres tipos de moléculas de
RNA, una población de moléculas grandes de RNA nuclear
de peso molecular sumamente variable. Estas moléculas
de RNA heterógeno
nuclear (hnRNA) son los precursores del mRNA maduro.
Otro grupo de moléculas de RNA pequeñas y también ubicadas
en el núcleo de las células eucarióticas se encuentran
unidas a proteínas formando unos complejos conocidos
como partículas de ribonucleoproteínas
pequeñas nucleares (snRNP o snurps), que desempeñan
un papel importante en la síntesis del mRNA. Por otra
parte, en el citoplasma también hay RNAs pequeños asociados
con proteínas específicas, algunos de los cuales desempeñan
un papel estructural, mientras que otros son necesarios
para la catálisis de ciertas reacciones; con lo que se está diciendo
que este tipo de RNA tiene o posee funciones enzimáticas.
El RNA es químicamente más reactivo que el DNA,
esto se debe al cambio de la 2´-desoxirribosa en el
DNA por la ribosa en el RNA; tal cambio puede parecer
insignificante y, sin embargo, afecta en gran medida
a las propiedades del RNA. El grupo 2´ hidroxilo o 2´
oxidrilo: 1) impide a las moléculas de RNA la adopción
de la conformación B-DNA; 2) permite que en las moléculas
de RNA ocurra un número mayor de interacciones terciarias;
3) promueve la reactividad química.
Un ejemplo que no se ilustrará- de lo antes
dicho es la importancia del grupo 2´-hidroxilo en el
comportamiento del RNA frente a las disoluciones alcalinas.
El tratamiento del RNA con un álcali
Se dijo antes (vide supra) que los genes bacterianos se
cotranscriben en operones; no sólo los bacterianos,
también los eucarióticos. A continuación, veremos la
teoría del operón lac, debida a Jacob y Monod, porque
es el primer ejemplo de cotranscripción en la historia
de
Sin tocar de manera teórica las mutaciones que
Jacob y Monod obtuvieron, la teoría puede expresarse
de la siguiente manera:
i = gen regulador activo.
z = gen estructural de la beta-galactosidasa.
y = gen estructural de la galactósido
transacetilasa.
x = gen estructural de la permeasa.
O = gen operador activo.
P = promotor.
o = operador.
La RNA
Se introduce en el cultivo al inductor (no confundir
con el gen inductor i), que es el azúcar lactosa el
inductor se une al represor, se forma el complejo represor-inductor
y
Tienen los mismos elementos
constitutivos, al que debe agregarse el Co-represor:
El gen que produce al co-represor sufre transcipción
y traducción, el represor inactivo no se une al gen
operador y hay transcripción y traducción para las proteínas
A y B.
EN
PRESENCIA DE CO-REPRESOR
El gen regulador sufre transcripción y traducción, el
represor se une al co-represor y
Este trabajo, que llevo muchos años, mereció
un Premio Nobel10, 11.
Ya se ha hablado de la transcripción, cuando se inició
la exposición del RNA (vide supra). Queda decir lo siguiente:
teniendo en cuenta la definición de gen, secuencia de
DNA que se transcribe, el origen de la transcripción
ha de considerarse como su punto de inicio, mismo que
se designa por +1 y su terminación como el punto donde
acaba. La transcripción de un gen comienza en su extremo
5´ y finaliza en el 3´- terminal. El desplazamiento
sobre gen según la dirección 5´→3´ se denomina
de avance
y en la dirección 3´→5´ se llama de
retroceso. Siguiendo el convenio adoptado para el
DNA, la cadena de DNA inferior es la cadena molde en
la transcripción, luego la cadena superior de DNA tiene
una secuencia idéntica a la del mRNA transcrito, a excepción
de los uracilos del mRNA, que equivalen a timinas en
el DNA.
Las secuencias del DNA en las que se ensamblan
los complejos de transcripción se llaman promotores.
En las células procarióticas hay cientos de promotores,
mientras que en las células eucarióticas hay miles,
ya que la transcripción de cada gen u operón se inicia
independientemente, dependiendo de la longitud del promotor.
Antes de 1975, los experimentos de construcción
de mapas genéticos demostraron que los promotores podrían
encontrarse en los extremos 5´-terminales de los genes
bacterianos y que estas regiones eran esenciales para
la transcripción. Sin embargo, hasta que se dispuso
de métodos rápidos para la determinación de la secuencia
de regiones del DNA, no fue posible conocer la estructura
primaria de los promotores. Los primeros genes secuenciados
de E. Coli no permitieron descifrar los elementos comunes obvios de los
sitios de formación de los complejos de transcripción.
Sólo cuando se dispuso de la secuencia de gran número
de genes se pudo obtener el patrón común de los promotores.
Estas secuencias patrón se llaman secuencias consenso, pues derivan del consenso de varios ejemplos.
Veamos los pasos sucintamente:
1.- El primer nucleótido que se transcribe
(designado por +1) generalmente es una purina.
2.- En la región -10, respecto del
origen, la mayoría de los genes contienen una secuencia
que se aproxima a
3.- En la región -35 la mayoría de
los genes tienen una secuencia parecida a TTGACA.
4.- Las regiones -10 y -35 están separadas
por 17 ± 1 nucleótidos.
La región -10 se conoce como la caja
TATA o como caja
de Pribnow, en honor de su descubridor, David Pribnow,
y la zona -35 se denomina región -35; ambas conforman
el promotor de la holoenzima de E.
Coli.
Los genes cuyos promotores se ajustan exactamente
a la secuencia consenso son muy pocos y, particularmente
en la caja TATA, en ajuste es muy pobre, apareciendo
Gs y Cs en lugares correspondientes a As y Ts. Otras
secuencias promotoras como las de los operones del RNA
ribosómico se parecen mucho a la secuencia consenso
y se transcriben, generalmente, con una elevada eficacia.
Éstas son algunas de las acciones de
La traducción genética y la biosíntesis de proteínas
se caracterizan por tres etapas: iniciación, elongación
y terminación. La traducción del RNA mensajero, una
vez asentado en el ribosoma, casi siempre se inicia
mediante la exposición del triplete AUG en un pliegue
que sigue a la porción llamada cap. La incorporación
del mRNA al rRNA ribosómico requiere de un factor de
iniciación proteico, llamado FI-3. Enseguida, se incorpora
el primer tRNA con participación de guanosintrifosfato
(GTP) y el factor de iniciación 2 (FI-2) para formar
una molécula compleja, que se une al anticodón correspondiente
al codón a triplete de mRNA mediante el factor de iniciación
1 (FI-1) y así empezar la biosíntesis del polipéptido.
Posteriormente, se incorpora a la fracción ribosómica
60S, se efectúa la hidrólisis del GTP y se integra el
ribosa 80S. El asentamiento del RNA de transferencia
de cada aminoácido ocupa dos lugares subsecuentes en
el ribosoma, el primero es el sitio A que corresponde
al aminoacil-tRNA para movilizarse al sitio P o peptidil-tRNA
en donde se incorpora el aminoácido correspondiente
en la cadena polipeptídica que está sintetizando.
La elongación o crecimiento de la cadena polipeptídica
se lleva al cabo con la integración del ribosoma 80S
con su lugar vacío A la formación de un compuesto entre
el aminoacil-tRNA correspondiente al codón por leer,
GTP y el factor de elongación (FE-1). Este compuesto
permite al aminoacil-tRNA entrar al sitio A con la liberación
del FE-1-GDP y P. El grupo -amino del aminoacil-tRNA,
incorporado al sitio A, se une a un grupo carboxílico
esterificado del peptidil-tRNA, que ocupa el sitio P
formando una unión peptídica mediada por la enzima peptidiltransferasa,
que se encuentra en la unidad ribosómica 60S. La reacción
produce un crecimiento del polipéptido en el sitio A,
moviéndose al sitio P y dejando vacío el sitio para
una nueva incorporación de otro aminoacil-tRNA. La translocación de una molécula de peptidil-tRNA
del sitio A al P se efectúa mediante el factor de elongación
2 (FE-2) y el GTP. La formación de uniones peptídicas,
la incorporación del aminoácido en el tRNA, la ubicación
del aminoacil-tRNA en el sitio A y la translocación
del peptidil-tRNA formado del sitio A al P, requiere
la participación de ATP y GTP como fuentes de energía.
La terminación de la síntesis de un polipéptido
se efectúa cuando aparece en el mRNA un codón terminal
para el cual no existe el anticodón correspondiente
al tRNA y que corresponde a los tripletes o codones
UAA o UAG, que ocupan el sitio A. Enseguida se llevan
al cabo la hidrólisis y la liberación del péptido terminal
y del aminoacil-tRNA, que ocupa el sitio P mediante
un factor liberador proteico, que es capaz de identificar
el codón terminal en combinación con la peptidiltransferasa
y el GTP, así la disociación del ribosoma 80S en subunidades
40S y 60S.
La traducción del mismo mRNA puede efectuarse
simultáneamente por varios ribosomas, constituyendo
polisomas o polirribosomas. Por consiguiente, los ribosomas
unidos en serie podrían correlacionarse con la longitud
del mRNA. Durante la biosíntesis proteica un solo ribosoma
puede traducir 40 codones por segundo. Los polirribosomas
adheridos al retículo endoplásmico dan el aspecto rugoso
que se observa al microscopio electrónico, e indican
los sitios de síntesis de proteínas secretadas por la
célula, previa conjugación en el aparato de Golgi, mientras
que los polirribosomas libres sintetizan proteínas que
se utilizan en el interior de la célula.
El concepto de cistrón
ha tenido que modificarse de acuerdo con los nuevos
conceptos que hay sobre genes discontinuos observados
en eucariotes. Por consiguiente, podría considerarse
que un cistrón
es la unidad que constituye un gen en procariotes y
la subunidad integral de un gen en eucariotes.
Un paso importante es el acontecimiento postraduccional
para remodelar las proteínas en su estado funcional
terminal. Hay varios ejemplos, entre ellos la insulina,
que presenta dos cadenas de polipéptidos unidas por
puentes disulfuro. Inicialmente se sintetiza como proinsulina,
se dobla sobre si misma para adquirir sus uniones disulfuro
y posteriormente una proteasa corta la porción acodada
de la molécula. Se modifican otras proteínas sintetizadas,
como las prohormonas eliminándose péptidos terminales
o fragmentándose en péptidos, como sucede con los factores
liberadores que actúan en la hipófisis, así como con
las moléculas de la colágena, que es sintetizada inicialmente
como procolágena. Se denomina supergén
a la porción de DNA que codifica mediante varios intrones
(vide infra) una molécula proteica citoplasmática, que origina diversas
subunidades funcionales.
Ciertos compuestos actúan inhibiendo la síntesis
proteica a nivel de la traducción del mRNA; algunos
actúan simulando el tRNA, como la puromicina, que se
incorpora en el sitio A como análogo de la tirosinail-tRNA.
Otros, como la toxina de Corinebacterium diphteriae infectado con
un fago específico, hace que se unan las ribosas en
el FE-2 (factor elongador) en las células de mamíferos
inhibiendo la biosíntesis proteica9, 12, 14.
Como se ha visto a lo largo de este trabajo, la función
primaria de los genes es codificar para la biosíntesis
de proteínas; ahora bien, la pregunta es: ¿en qué forma
la secuencia de las cuatro bases del ADN determina la
secuencia de los 20 aminoácidos de las proteínas?, ¿cuál
es la secuencia específica de las bases que codifican
para un aminoácido en particular? La longitud teórica
mínima de las unidades de codificación, o sea, de los
codones, es de tres bases. Si fuera de una base, sólo
se podrían codificar cuatro aminoácidos, uno para cada
una de las cuatro bases y si fuera de dos bases podrían
codificarse únicamente 16 aminoácidos. Con unidades
de codificación de tres bases, que es como funciona
el código genético, se tienen 43 = 64 tripletes diferentes, cantidad más que suficiente
para codificar a los 20 aminoácidos que forman la secuencia
de cualquier proteína. Lo anterior implica que un aminoácido
puede ser codificado por más de un codón y por ello
se dice que el código genético es degenerado; en lo
personal, prefiero usar el término polisémico,
para calificar esta propiedad del código genético. Por
otro lado, algunos tripletes no son codificadores, pero
su función también es importante, puesto que sirven
para indicar dónde empiezan y termina la lectura de
un mensaje, a manera de espaciadores, función comparable
a la de la puntuación y separación de las palabras de
la lengua ordinaria. Veamos cuál es el código genético.

La información contenida en los genes eucarióticos se
encuentra frecuentemente interrumpida por secuencias
que no aparecen en el producto final el RNA. Estos intrones o secuencias intercaladas resultaron ser una característica común de
los genes y los RNA(s) primarios de transcripción de
la mayoría de los organismos eucariotes y de algunos
procariotes.
Los intrones se eliminan de las moléculas de
RNA por el proceso conocido como ruptura (splicing)
o montaje del RNA, que ocurre meticulosamente y origina
el RNA funcional encargado de mantener el flujo de información
biológica desde el DNA a una proteína. La ruptura parece
más difícil en un principio que cualquier otra forma
de procesamiento del RNA ya que la etapa inicial es
la quiebra de un único transcrito en dos fragmentos
distintos que deben permanecer asociados para ser, a
continuación, soldados en una única molécula madura
de RNA. Para que el RNA mantenga su contenido informativo,
su escisión y su posterior soldadura deben ocurrir en
la posición correcta y de forma rigurosa. Así, el desplazamiento
de un solo nucleótido podría originar un RNA estructurado,
como un tRNA o un rRNA, pero afuncional u organizar
un mRNA que dirija la síntesis de una proteína inactiva.
El procesamiento del RNA está catalizado por
enzimas, cuyo análisis constituyó una sorpresa, ya que
algunas de estas enzimas están constituidas por RNA
y no por proteína. Además, algunas de estas moléculas
activas de RNA están localizadas en los propios intrones,
donde autocatalizan su eliminación. Por lo consiguiente,
el descubrimiento de los intrones ha alterado significativamente
el concepto de evolución de los genes y de la estructura
proteica.
ESQUEMA
DE UN COMPLEJO INTRONES-EXONES
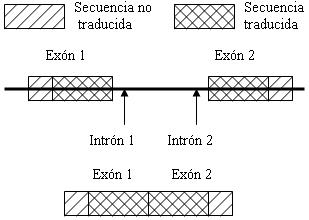
Obsérvese la
ruptura (splicing) de los exones y los intrones, y
la soldadura de los exones 1 y 2.
Las secuencias en el DNA y el RNA maduro se denominan
exones. La formación de una molécula madura y continua de RNA se consigue
mediante la escisión del RNA, que implica una primera
etapa de eliminación de intrones y una segunda de soldadura
de los exones.
El punto de referencia de una reacción de escisión
está contenido en el propio intrón. En el producto primario
de transición cada intrón está intercalado entre dos
exones (ver esquema), el primero situado en 5´ respecto
del intrón y el segundo en posición 3´ respecto del
intrón. La región-frontera entre el exón en 5´ y el
intrón se conoce como sitio o conexión 5´ de splicing,
o sea, de escisión o ruptura, y, análogamente la región-frontera
entre el intrón y el exón 3´ se denomina sitio o conexión
3´ de escisión. Los sitios de ruptura o escisión están
formados por dos nucleótidos en ambos lados de los enlaces
fosfodiéster que se rompen, pero si los sitios de ruptura
forman parte de la secuencia consenso para la reacción
de ruptura, éstos pueden estar formados por más de dos
nucleótidos.
En algunas especies el tamaño de los intrones
oscila entre 14 y 46 pares de bases. Las levaduras contienen
alrededor de 400 genes nucleares de tRNA, de los cuales
el 10% contiene un único intrón.
Fue en 1977, cuando Hall, Olson y Goodman aislaron
y secuenciaron cuatro de los ocho genes que codifican
para el tRNA. Así,
Volviendo a los intrones, después de su eliminación
el intrón todavía es activo y puede catalizar una o
dos reacciones de autociclación. Apareciendo más en
eucariotes, no son ajenos a los procariotes. Así, en
Tetrahymena
el proceso de auto-escisión no es una reacción verdaderamente
enzimática porque el catalizador originario no se renueva
durante el curso de la reacción.
Con los exones y los intrones se muestra la organización
de un gen típico que contiene intrones. Los exones son
las partes del gen que darán lugar a la secuencia del
RNA maduro, por lo que contienen la información que
se requiere para la biosíntesis de proteínas. Así mismo,
los exones comprenden tanto la secuencia guía 5´ que
precede a la región codificadora como el fragmento 3´
que se encuentra entre la región codificadora y el RNA
maduro. Se citan algunas otras propiedades de los intrones:
1.- En todos los genes eucarióticos
sin excepción, la secuencia GU se encuentra en el punto
en el que el extremo 5´-terminal del intrón se une al
exón 5´.
2.- La secuencia dinucleotídica AG
marca el punto de unión del extremo 3´-terminal del
intrón con el exón 3´.
3.- Un residuo de adenosina situado
unos 40 nucleótidos más arriba del sitio de escisión
3´ forma parte de un sitio llamado de ramificación.
El complejo de escisión o ruptura posee un gran
tamaño molecular (unos 3 x 103 kd) así como
distintas subunidades. Las moléculas de RNA constituyen
el llamado RNA nuclear de pequeño tamaño (snRNA), asociándose
con proteínas para formar las ribonucleoproteínas
nucleares de pequeño tamaño (snRNPs) estas partículas
son esenciales en los proceso de escisión y en otras
funciones celulares, algunas de ellas que cursan con
patología. Así, las enfermedades autoinmunes comprenden
una serie de Síndromes tales como el lupus eritematoso
sistémico, la artritis reumatoide y la enfermedad mixta
del tejido conectivo. Estas enfermedades se denominan
así porque los individuos que las padecen sintetizan
anticuerpos dirigidos contra sus propios tejidos y componentes
celulares, incluyéndose aquí el DNA, las inmunoglobulinas,
los glomérulos renales y las neuronas. Además, suele
tratarse de enfermedades multisintomáticas, destacando
entre estos síntomas la inflamación de los tejidos.
En muchas ocasiones se trata de enfermedades que conducen
a la muerte.
Los pacientes con enfermedades autoinmunes suelen
producir anticuerpos contra los componentes nucleares.
En 1977, Joan Steitz y sus colaboradores analizaron
el suero de un paciente con enfermedad mixta del tejido
conjuntivo con el fin de identificar las partículas
unidas a dichos anticuerpos. En un principio pensaron
que los anticuerpos iban dirigidos hacia las hnRNPs
(ribonucleoproteínas nucleares heterogéneas), aunque
luego observaron que también reaccionaban con otras
ribonucleoproteínas nucleares. Después de que cinco
de ellas hubieran sido identificadas, se observó que
estas snRNPs participaban en la retirada de los intrones.
El empleo de sueros de pacientes con enfermedades autoinmunes
permitió la caracterización más a fondo de estos componentes
nucleares.
Existen dos posibles hipótesis para explicar
por qué los sueros de estos pacientes contienen anticuerpos
frente a las snRNPs. La primera afirma que las snRNPs
se encuentran en el núcleo físicamente separadas de
los componentes del sistema inmune, pudiendo ser liberadas
a la sangre por la lisis de la célula e inducir entonces
la síntesis de anticuerpos. La segunda sugiere que los
anticuerpos aislados por Steitz y sus colaboradores
podrían no estar dirigidas contra las snRNPs per se, sino contra otras proteínas de
estructura similar, tales como ciertas proteínas virales8, 12.
Como he pretendido demostrar a lo largo del presente
trabajo, las diferencias entre
No se hace ciencia por hacer ciencia, se hace
ciencia para conocer y para aplicarla a ese conglomerado
al que llamamos sociedad, así como a su célula: el hombre.
Trátese de ciencia teórica (toda
ciencia por definición es teórica) o aplicada, el
resultado es por y para el hombre.
Escribí estas páginas sin olvidar la historia
de la ciencia porque se entiende mejor el ethos
humano cuando se conoce la historia de lo sucedido.
Por otra parte, dejo entrever que
Para hacer ciencia, como ha sostenido Jesús Mosterín,
se necesitan conceptos: Así como no se puede dibujar
sin líneas, ni se puede pintar sin colores, tampoco
se puede hablar ni pensar sin conceptos. Esto vale tanto
para la vida cotidiana como para la actividad científica.
De hecho, muchos de los conceptos científicos actuales
provienen de conceptos cotidianos, aunque durante el
viaje se han transformado, ganando sobre todo en precisión.
Así, las nociones químicas de hierro (átomo con 26 protones
en su núcleo) o de agua (H2O) precisan nociones previas del lenguaje ordinario.
Es usual dividir los conceptos científicos en clasificatorios,
comparativos y métricos17.
En el presente trabajo se han usado precisamente
estos tres tipos de conceptos, como el lector atento
podrá ver. También se han hecho relaciones binarias,
teniendo en cuenta que entre objetos de un dominio A
es una relación de equivalencia, y por tanto binaria,
sí y sólo sí es reflexiva, simétrica y transitiva, en
este dominio y si A = B y B = C, entonces A = C. Con
esto se está diciendo que el trabajo ha sido dirigido
por
-
- Emery
A. E. Methodology
in Medical Genetics. 4ª ed.
- Mendel G. Versuche
über pflanzen-hybriden. USA. J. Hered. 42. 1-47.
1974.
- Ford E.
B. Mendelism
and Evolution. 2ª ed. Londres. Ed. Methuen &
Co Ltd. 1984.
- Garrod
A Sir. Inborn
Errors of Metabolism.
- Scriver
C. R. y col. The
metabolic basis of inherited disease.
- Davidson
J. N. The Biochemestry
of the Nucleic Acids. 8ª ed.
- Vogel
F. y col. Human
Genetics. 3ª ed.
- Murray R. K. y col. Harper´s Biochemestry.
16ª ed.
- Allende J. Biosíntesis
de Proteínas y el Código Genético. 6ª ed. Santiago. Ed. OEA. 2004.
- Lehninger A. Bioquímica.
2ª ed. Barcelona. Ed. Omega. 1986.
- Stent
G. S. Molecular
Biology. 4ª ed.
- Harris
H. The Principles
of Human Biochemical Genetics. 9ª ed.
- Weatherall
D. J. The new
Genetics. 4ª ed.
- Ochoa S. Base
Molecular de
- Kuhn T. S. La
estructura de las Revoluciones Científicas. Nueva
ed. México, D. F. Ed. Fondo de Cultura Económica.
2004.
- Mosterín J. Los
conceptos científicos. En La ciencia: estructura
y desarrollo. C. Ulises Moulines ed. España. Ed. Trotta.
1993.